Track Down a Ruby Memory Leak Issue
Background⌗
I found that our production instances memory utilization exceeded the threshold frequently in the past few weeks. This was what it looked like:
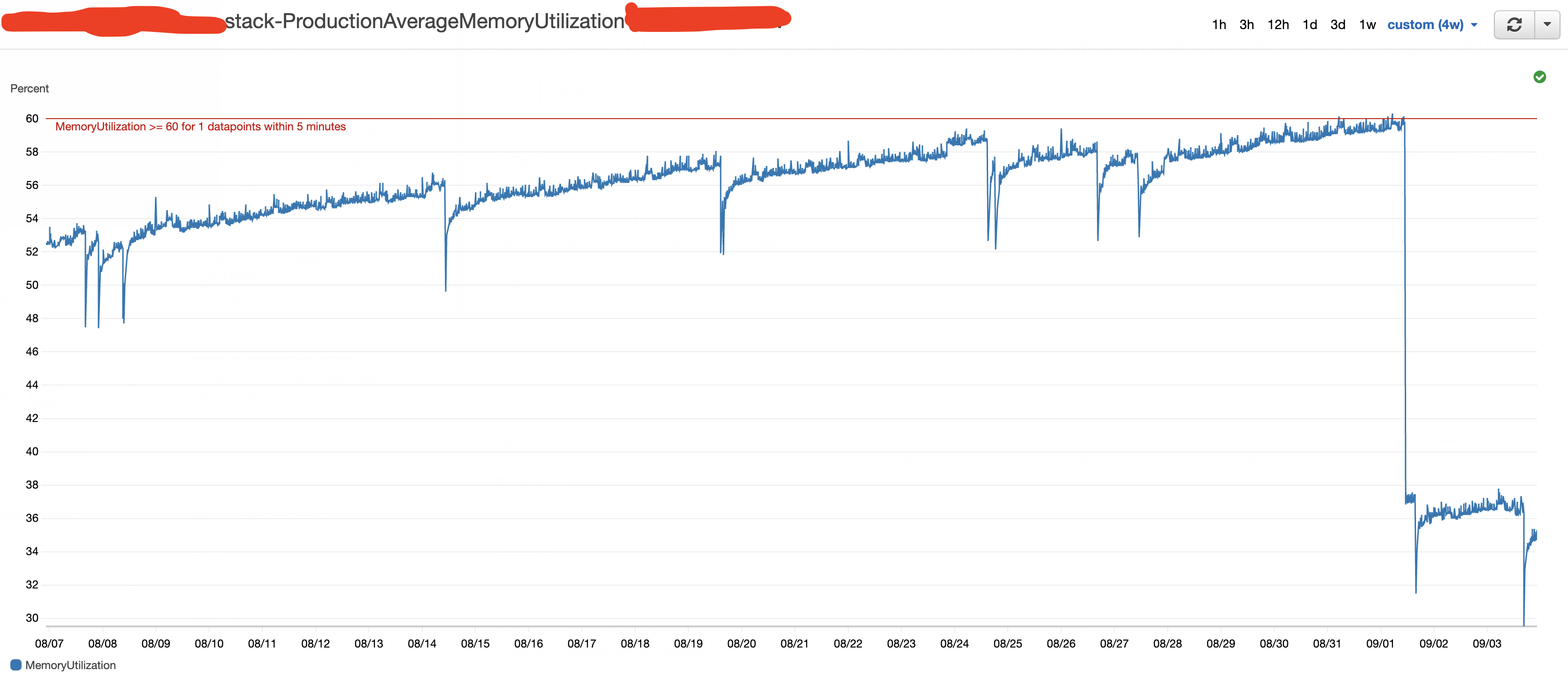
In the past one month (even longer), there’s an incremental memory consumption in our application. And one day, it exceeded the line.
Actually, the same had been happening to our test instance for a long time, due to many cron jobs that won’t exit as expected. As time goes by, more and more memory was consumed by them.
Had the experience in mind, I checked the processes in production instances:
ps -e uf
As it turned out, process crond forked many children processes whose STAT were sleep . And they were all scheduled by a gem called whenever. If everything went as expected, these processes would usually exit in seconds.
However, some of these processes started even months ago.
I decided to dive in.
Trace Back to Source⌗
Let’s check the system call of crond :
sudo strace -p <pid>
The output showed that the system call was wait4() , which meant that it’s waiting for its children processes to exit, which they didn’t.
Checked all the stuck children processes, and their system calls were all
futex(0xAddress, FUTEX_WAIT_PRIVATE, ...)
The futex() system call provides a method for waiting until a certain condition becomes true. It is typically used as a blocking construct in the context of shared-memory synchronization. When using futexes, the majority of the synchronization operations are performed in user space. A user-space program employs the futex() system call only when it is likely that the program has to block for a longer time until the condition becomes true. Other futex() operations can be used to wake any processes or threads waiting for a particular condition.
That’s unexpected, because none of our cron jobs were involved in threads. And cron jobs scheduled by crontab behaved as expected. Cron jobs scheduled by our Rails application, however, were all stuck. So I could narrow down to Rails application.
Our cron jobs were scheduled by gem whenever, let’s see what commands were executed exactly:
bundle exec whenever
Output:

The output showed that rake or rails runner were executed through bundle , and the fact was that both commands got stuck.
I got two suspects:
- There’s a bug in bundler
- There’s a common issue while executing Rails cron jobs, sucha as common gems, dependencies, middleware, etc.
Next up, I used gdb to inspect the calling stack of a stuck process (in C):
sudo gdb -p <pid> info stack
Output:

The output showed that the final call was pthread_cond_wait, and so were other stuck processes.
I found rb_thread_terminate_all() very appealing, so I googled it, and this article showed up, which was very helpful:
It turned out that Ruby would mark a thread to exit with rb_threadptr_to_kill() :
static void
rb_threadptr_to_kill(rb_thread_t *th)
{
rb_threadptr_pending_interrupt_clear(th);
th->status = THREAD_RUNNABLE;
th->to_kill = 1;
th->errinfo = INT2FIX(TAG_FATAL);
TH_JUMP_TAG(th, TAG_FATAL);
}
Information on errors would be stored in errinfo if there was an exception during execution.
Let’s inspect the information about current Ruby thread:
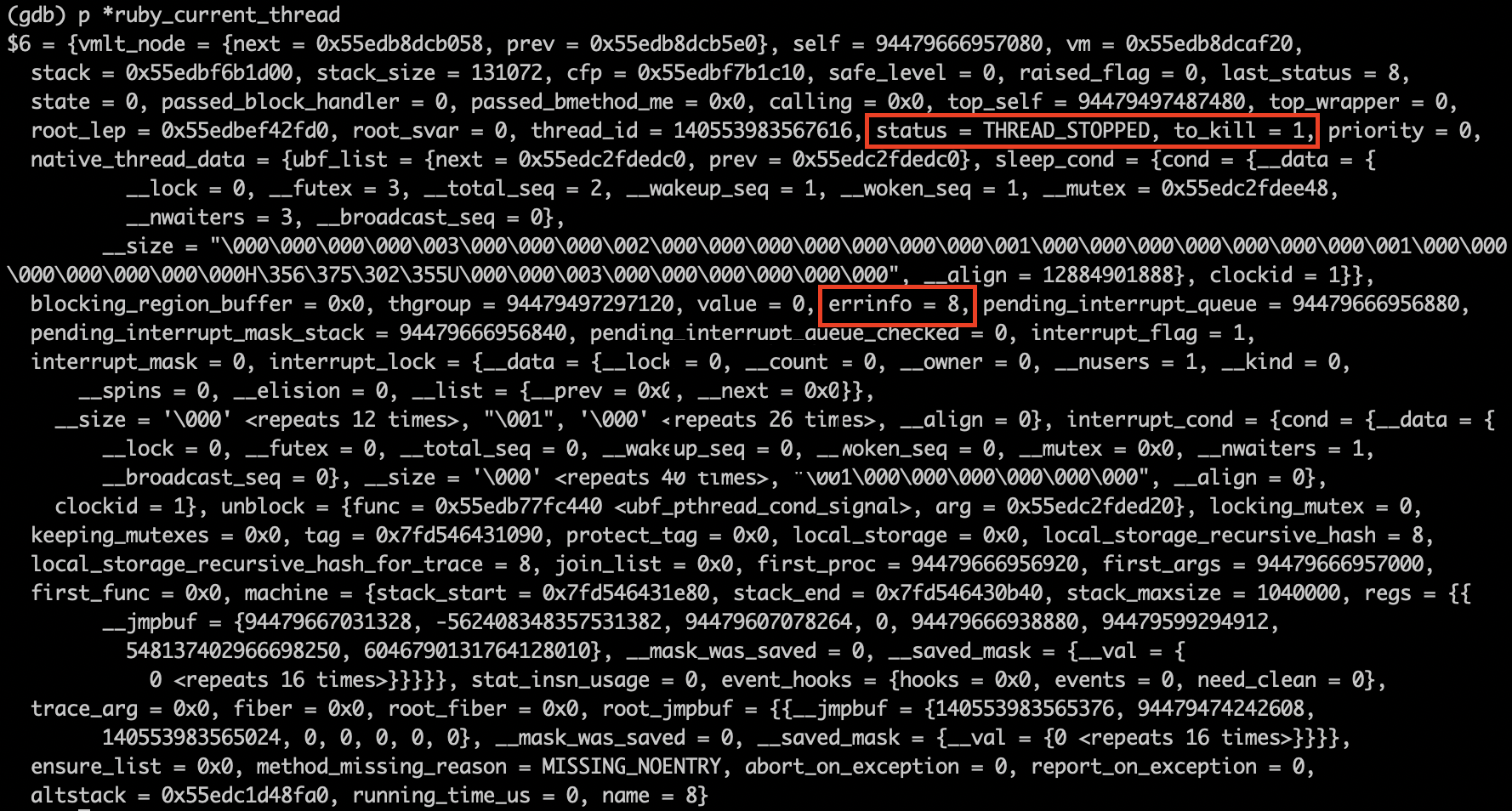
The output told me that current thread was marked as THREAD_STOPPED and to_kill was 1 . However, the errinfo was 8 (0x08, nil in Ruby).
Some kind of error interfered with Ruby VM’s maintenance of threads, causing threads won’t exit as expected.
Ruby code to reproduce:
Thread.new do
loop do
puts "Loop start"
begin
begin
sleep
ensure
raise
end
rescue => e
p e
end
end
end
Which meant:
- A
loopin a thread beginandrescuewithin the loopbeginandensurewithin the outerbegin- Exceptin within
ensure, catched by the outerrescue
The outer rescue made Ruby VM decide that everything was ok with current thread and would not be killed because of the exception.
In short, it’s a Ruby bug.
However, I could not find what on earth caused this issue in C. The quickest solution is to make sure NOT to raise any exception inside an ensure block.
Next thing was to locate the problematic Ruby code.
Let’s check the threads within a stuck process:

(The issue was resolved when I’m writing this article, output above was reproduced.)
The rake task was executed through bundle, so ID 1 was the bundle thread. And ID 2 was the thread of the script I wrote to reproduce the bug.
After thorough inspection, I found that the problematic code was located in a file called “agent_thread.r*”, which belonged to a gem: newrelic_rpm.
The cause was that if the process exited while receiving gzip-encoded request via Net::HTTP , Zlib::BufError would be raised when finish was called, which was inside an ensure block:
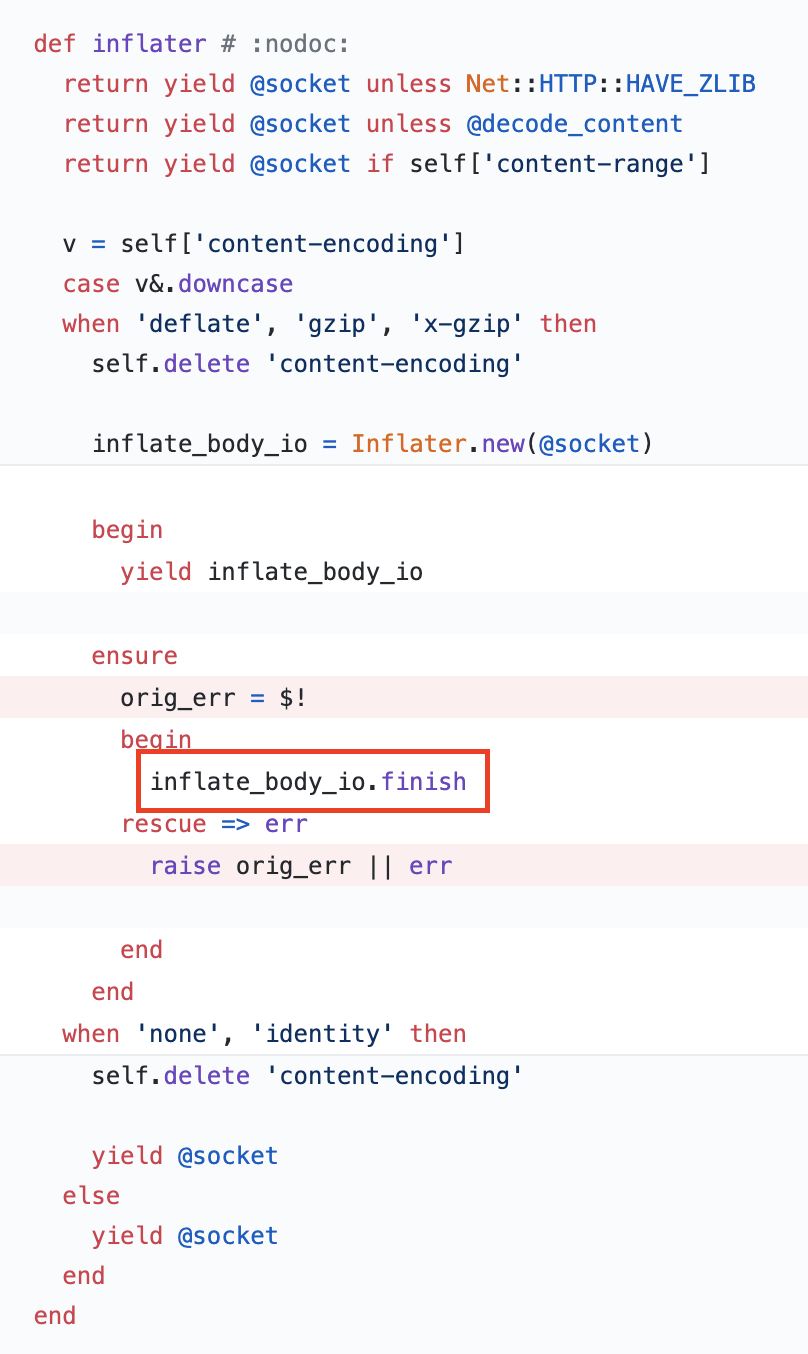
Now it’s been fixed (2020-05-31), in Ruby:
https://github.com/ruby/ruby/pull/3164
Solution⌗
Now it’s easy to solve the problem:
Disable New Relic when Rails runs cron jobs, and New Relic is unnecessary in our cron jobs.
Just add one line in schedule.rb:
env 'NEW_RELIC_AGENT_ENABLED', false
Outcome⌗
Since the day I fixed the problem (2020-09-07), no stuck process was found.
I’ll keep observing.
Reference⌗
https://developer.aliyun.com/article/6043
https://medium.com/@zanker/finding-a-ruby-bug-with-gdb-56d6b321bc86
https://bugs.ruby-lang.org/issues/13882
https://github.com/ruby/ruby/pull/3164
https://blog.arkency.com/2016/04/how-i-hunted-the-most-odd-ruby-bug